


|
|
|
With today's technology, it is possible to access process data from machines and machine peripherals. However, merely recording and storing data is not enough to generate added value. In order to use machine data meaningfully, it must first be processed in such a way that everyone can understand what each data point represents in the real world.
In order for data to be understood, it must be provided with context – that is, information that describes the data. We refer to this process as contextualization.
In this article, we provide insight into how these tools work, why digitization projects become simpler and faster with such an approach, and what the process looks like in detail.
Efficient Complete Solution for Contextualization and Analysis
At ENLYZE, we have developed tools that enable new data points to be created and contextualized in just a few minutes. New machine data points can be added to the ENLYZE platform, relevant context can be attached to the data, and the data can be used for analysis as well as in dashboards.
We have paid special attention to allowing our customers to carry out this process themselves without needing external or internal IT specialists.
This approach offers enormous benefits: The system can be continuously adapted to changing requirements. Since every employee can implement the changes independently, modifications in the dashboard are almost instantly available. Furthermore, the motivation of everyone increases, as they are empowered to work independently and without external dependencies. Problems in production can be solved data-driven and more efficiently.
Why So Few Companies Are Digitized
Digitizing plants/machines poses two major challenges:
Reading data from the plants
Processing the data to make it usable
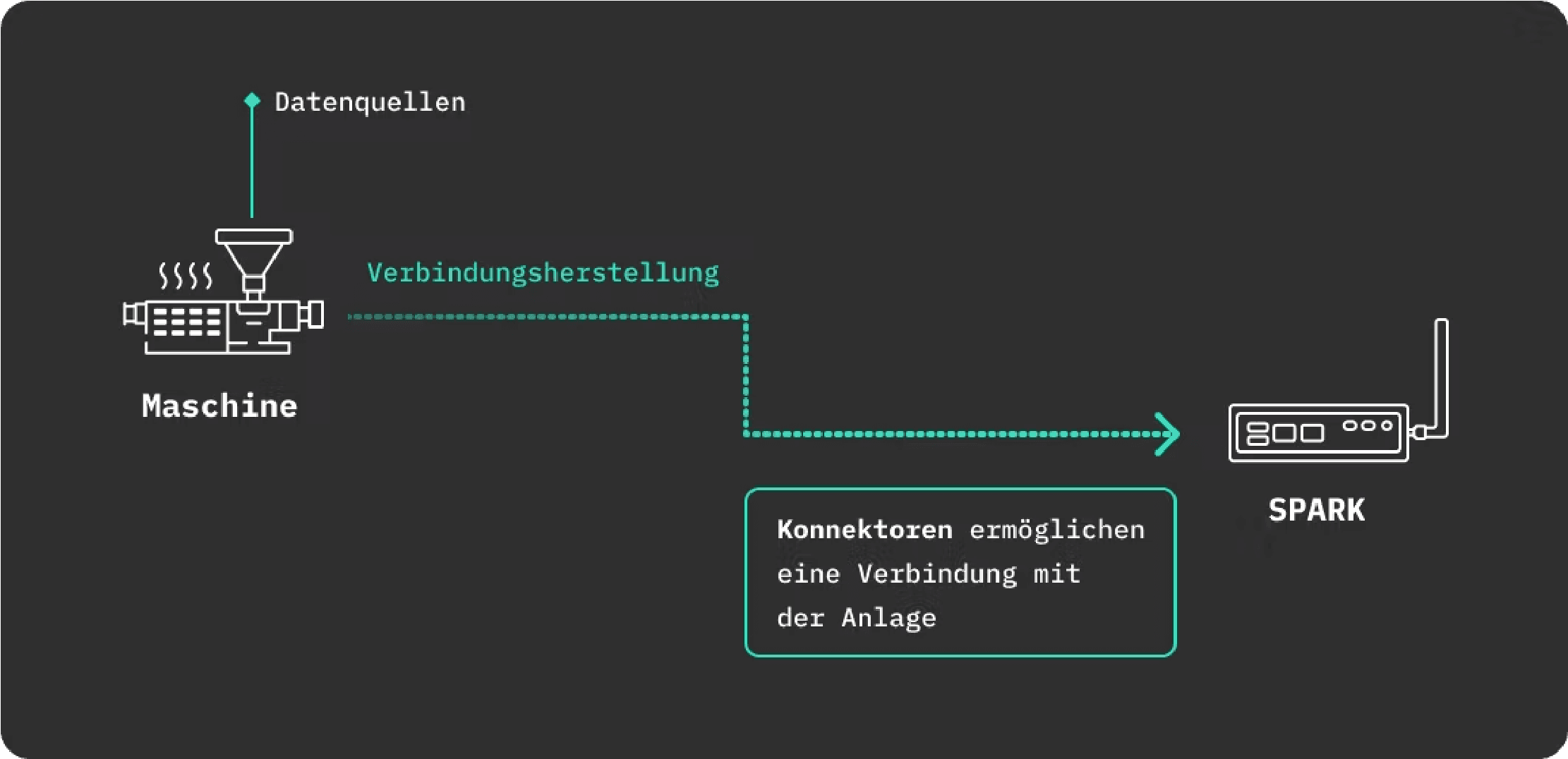
Reading the data usually requires a combination of software and hardware. The hardware establishes the physical connection to the plant, while the software acts as a translator for the respective communication protocol of the plant.
For more on the topic and how we solve the problem with our edge device SPARK, you can find this article.
Once the physical connection and the appropriate protocol are available, data can be read from the machine. The issue regarding reading the data is thus resolved.
Processing Data to Make It Usable for Everyone
The data was originally intended for internal use by the machine itself and often has cryptic designations. Frequently, the designation of the data points consists of just a few letters and numerical values.
The data points cannot be easily interpreted by a human. Therefore, the data points must first be "translated".
We call this "translation" contextualization. Here, the data point is given a meaningful designation.
For example, the internal designation on the PLC Temp_regler_01_K1_03 is translated to Actual Temperature Heating Zone 1. How exactly this translation is achieved will be clarified later in the text.
Additionally, the data point is assigned a unit. In this example, it pertains to a temperature, so °C is chosen. If necessary, the value can also be scaled. A detailed explanation of this will follow later. After this information is added to the data point, it is contextualized.
Only by adding context is the data point and what it represents understood by everyone. This makes the data easily accessible to all users, allowing everyone from production to controlling to utilize the data point for analysis or in dashboards.
Conventional Approach of Other Providers
Until now, contextualization has been costly and time-consuming. The reason for this is the need for expertise from two different areas. On one hand, specialized knowledge about the plant and the process is required, and on the other hand, IT knowledge is necessary to connect to the system, attach context to the data points, and store the data points permanently.
Today, this task is usually undertaken by engineering firms or automation technicians. Typically, the implementation by external service providers takes 5-10 working days and costs accordingly.
However, with this conventional approach, there are significant friction losses between the involved process engineers and IT.
The process engineers must inform IT of which data points are required. Once IT has identified all the supposed data points, these are validated together with the process engineer. After successful verification, the data points are then permanently stored in a system with the help of IT.
For the entire process from selection, validation, to permanent storage, at least two departments (or external partners) are needed, leading to costs and effort for coordination and project management.
💡 With the conventional approach, external service providers with the corresponding expertise are needed to make adjustments. Making modifications afterward is time-consuming and expensive.
The ENLYZE Approach
The complete solution offered by ENLYZE for contextualization is based on automating manual tasks and empowering process engineers to carry out the process without IT specialists.
For this, our edge device SPARK is first integrated into the company network together with IT and connected to the plant. From this point on, data can be read from the plant. More information about SPARK and its functionality can be found here.
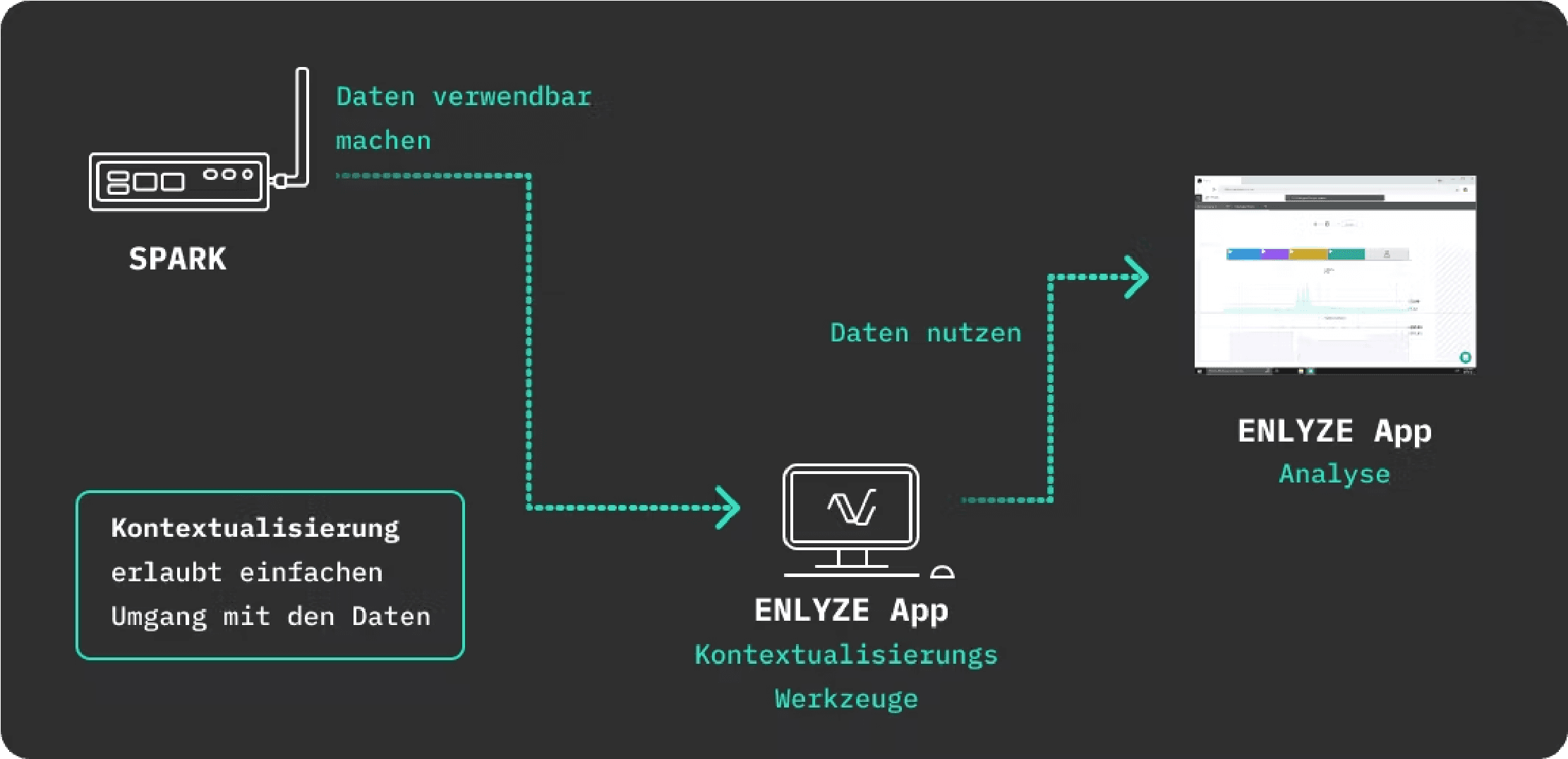
All further steps for the complete digitization of your systems can now be conducted independently of location in the ENLYZE app and without IT support.
Contextualization in the ENLYZE App
Once the connection with the plant has been successfully established, all relevant data points can be identified, contextualized, and permanently recorded using the ENLYZE app. This way, anyone can meaningfully work with the data afterward and understands what each data point entails.
The process is divided into 3 steps:
Get an overview of all data points
Explore data points
Contextualize data points
1. Get an Overview of All Data Points
In the ENLYZE app, all data points from the respective data sources (PLC, sensor, etc.) are automatically listed. In addition, all relevant information that the data source provides for the respective data point is displayed (such as the comment of the PLC programmer).
The listed data points can now be searched and filtered based on attributes such as data type, data block, etc. This way, relevant data points can be found as quickly as possible.
✅ Benefit for companies: All data points are clearly listed. The search and filter functions help quickly identify relevant data points – a particularly useful feature, as the number of data points can quickly reach into the thousands.
2. Explore Data Points
Data points exported directly from the data source are often cryptically labeled. Therefore, it is difficult to find all data points at first glance or to identify the correct ones.
The meta-information of a data point from a PLC of type S7-300 looks like this:

These are the only pieces of information that the S7-300 initially provides.
Based on this information, a data point cannot be identified unambiguously.
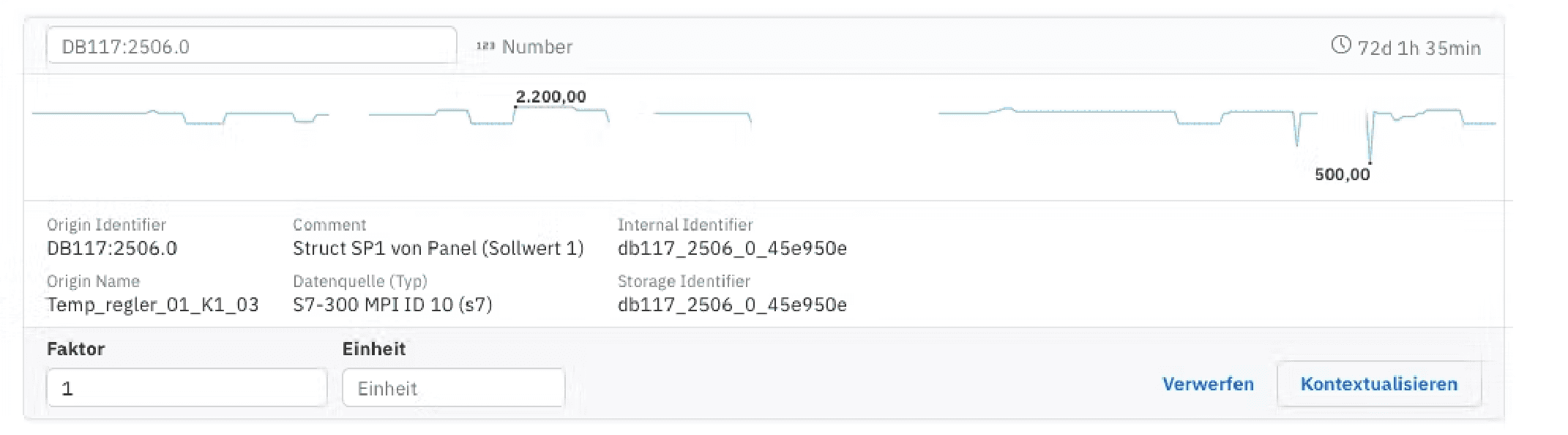
However, one can assume: It is likely a temperature, possibly that of Heating Zone 1.
To verify this assumption, our exploration feature can be utilized.
The data point can be explored with one click – continuously recorded and visualized: In addition to the existing meta-information of the data point, the temporal progression of the data point can then be used to identify it unambiguously.
While a data point is being explored with the ENLYZE app, it is ideal to take 2-3 photos of the HMI and the displayed values of the process parameters. These pictures (process parameter values from the HMI) can then be matched with the progression of the explored values from the ENLYZE app, through a comparison of the timestamps. This approach allows for a clear assignment of all data points.
If it turns out during the matching that the explored process parameter is a data point that should not be recorded, it can simply be discarded and will not be recorded further.
✅ Benefit for companies: Through the exploration feature, you obtain not only all meta-information of the data point from the PLC, but can also conveniently observe the data points over time. In combination with photos of the HMI, this enables a quick and clear assignment.
3. Contextualize Data Points
During the contextualization process, a clear name, scaling factor, and unit are defined.
Defining a Clear Name:
Once a data point has been unambiguously assigned, it can be given a human-understandable clear name.
In our example: Temp_regler_01_K1_03 → Actual Temperature Heating Zone 1
This transforms the cryptic name of the PLC into a human-readable clear name. Based on the clear name, everyone understands what the data point represents.
Scaling Data Points:
Due to the way PLCs are programmed, however, values often need to be scaled. In our example, the value 2200 is provided by the PLC (see image below). Our experience tells us that temperatures over 250°C in Heating Zone 1 cannot occur.
A comparison with the HMI images provides clarification. The temperature at that time was 220.00°C. Therefore, a scaling with the factor 0.1 must be performed. Scaling can be done effortlessly through the scaling factor in the ENLYZE app.
Adding a Unit:
A unit must be defined for each data point. Only in this way is the value of a data point clearly defined.
In our case, it refers to a temperature: Therefore, we choose the unit °C.
Below is the contextualization of the data point in the ENLYZE APP:
All necessary information has now been added to the data point. From a data point that was initially not clearly identifiable, it has become the data point with the clear name Actual Temperature Heating Zone, which indicates values in °C. With this information, everyone in the company understands what this data point represents and how to work with it.
By clicking the Contextualize button, this information is attached to the data point. From now on, the data point will be permanently streamed into the ENLYZE platform and can be used by you and your colleagues for analysis and creating dashboards.
Through the process of contextualization, information is therefore assigned to a data point that unambiguously identifies it, is permanently preserved, and made accessible to all colleagues.
The advantage is clear. The data point and its representation are now understood by everyone. Only then can meaningful and quick analyses be conducted by all employees.
✅ Benefit for companies: After contextualization, everyone can work with the data points without issues. This enables quick handling of the data in analyses and dashboards.
Adjusting and Setting Up the System Without IT Capacity
Once our system has been integrated with the help of your IT, adjustments can be easily made by users themselves. Adjustments to the system, such as adding or removing a data point, can also be made without expertise. The previously necessary IT steps have been automated in our system.
Through this approach, our customers benefit in multiple ways:
IT resources are saved: IT is only needed for the initial integration
Employees can adapt the system to their needs themselves
Unnecessary coordination tasks between IT and domain experts for data selection are avoided
✅ Benefit for companies: Employees are empowered to adjust the system themselves. This increases motivation, reduces bound IT capacity, and saves time and costs for project management.
Read more


