


|
|
|

Können Sie aus dem Stand sagen, wie die Temperaturen und Drücke auf den Steuerungen Ihrer 24 Maschinen mit 5 verschiedenen Steuerungen heißen? Falls Sie diese Maschinen zufällig nicht vor 2 Wochen selbst programmiert haben, lautet die Antwort höchstwahrscheinlich “Nein”. So geht es fast all den Unternehmen, mit denen wir sprechen.
Bei der Programmierung der Steuerung entscheiden SPS Programmierer:innen über die Benennung der Mess- und Regelgrößen. Man kann also nicht einfach “den Durchsatz” anfordern. Dieser verbirgt sich dann hinter solch kryptischen Bezeichnungen, die wir auf Steuerungen gefunden haben:
Durchsatz_A
A2_ftpt_svktpt_a0
A_EXT_ACT_KGH
P_Netta_Estrusore_A_KgH
section[1].extruder[1].throughput.act
Dass dann Steuerungen auch mal mehr als 100.000 Variablen aufweisen, macht die Suche nach den wenigen Relevanten zur Geduldsprobe. Wir zeigen erst, wo und warum es hakt und erklären dann, wie eine harmonisierte Datengrundlage dazu führt, dass diese Arbeit einmal und dann nie wieder gemacht werden muss.
Übersicht Blogreihe Konnektivität & Maschinendaten:
Digitalisierungs-Dilemma: Für die Daten arbeiten oder mit den Daten arbeiten
Von Euromap, Datenblöcken und harmonisierten Daten
Mit ENLYZE und Grafana bereit für alle Herausforderungen in der Produktion
Lektion #3: Die richtigen Datenpunkte auf der Anlage finden: Die Suche nach der Nadel im Heuhaufen
In einer perfekten Welt steckt man ein Kabel in die Steuerung und die gewünschten Temperaturen, Drücke und Geschwindigkeiten werden aufgezeichnet. Leider ist dies jedoch nicht der Fall und die richtigen Werte müssen erst gefunden werden, bevor sie aufgezeichnet werden können.
🏷️ Menschen denken in Drücken und Durchsätzen - Steuerungen denken in “Datenblöcken” und “Tags”
Jede Steuerung besteht aus Datenpunkten, die den Produktionsprozess steuern und überwachen. Dazu gehören eine Vielzahl von Soll-Vorgaben, Ist-Werten, Grenzwerten und Indikatoren über den Zustand eines Aggregats (Ein/Aus). Auch Textfelder, wie die Angabe des verwendeten Materials, sind als Datenpunkt vorhanden. Im Kontext von OPC spricht man von Tags oder bei S7-Steuerungen von Datenblöcken. Wir nennen diese allgemein Variablen.
Das Problem: Es gibt keinen globalen Standard für die Benennung von Variablen bestimmter Prozessgrößen, wie zum Beispiel Drücke, Temperaturen oder Durchsätze. SPS-Programmierer:innen entscheiden dies nach internen Schemata. Konkret bedeutet das: Um die Temperatur einer Siemens S7-1200 auszulesen, kann der Wert hinter DB20:1, DB40:3 oder einem anderen Datenblock versteckt sein.
Die Unterschiede entstehen durch die verwendete Hardware (Siemens S7, B&R usw.), das Protokoll und den Aufbau der Anlage selbst. Selbst bei Anlagen desselben Herstellers kann man sich nicht sicher sein.
Tatsächlich ist es eher die Regel, dass selbst diese unterschiedliche Datenblöcke und Tags für dieselben Prozessgrößen aufweisen, wenn sie aus verschiedenen Produktionsjahren stammen.
🇮🇹 Parla Italiano?
In all unseren Kundenprojekten zeigt sich ein ähnliches Bild: Kein Unternehmen besitzt ausschließlich Anlagen von einem einzigen Hersteller. In einem globalen Markt werden auch global Anlagen erworben, und häufig wählen SPS-Programmierer:innen Variablenbezeichnungen in ihrer jeweiligen Landessprache. So finden sich bei Anlagen aus Deutschland, Italien und England entsprechend deutsche, italienische und englische Variablennamen auf den Steuerungen. Hinzu kommt die Verwendung von nicht standardisierten Abkürzungen, welche die Mischung perfekt machen.
Viel Glück, Buona Fortuna und Good Luck!
🗺️ Was ist mit Euromap und Co?
Euromap wird auf Messen häufig als Buzzword und ultimative Lösung für alle Probleme präsentiert. Unsere Erfahrungen zeigen jedoch, dass die Realität anders aussieht.
Die Euromap-Standards sind Spezifikationen, die für die Kunststoff- und Kautschukindustrie entwickelt wurden und entweder eigenständig oder als OPC UA Companion Specifications existieren. Vereinfacht gesagt, definieren sie einheitliche Namen für Variablen, die in verschiedenen Anlagen dieselben Prozessgrößen repräsentieren.
Das klingt zunächst vielversprechend, hat aber einen Haken: Die Spezifikationen konzentrieren sich auf eine sehr kleine Gruppe von Variablen, die hauptsächlich für einfache Anwendungsfälle wie die Übertragung aggregierter Werte an das MES relevant sind.
Sobald man diesen Pfad verlässt, stößt man schnell an die Grenzen des Euromap-Standards. Zum Beispiel ist ein Stapelautomat und dessen Prozessgrößen nicht Teil einer einzigen Spezifikation.
Weiterhin haben wir schmerzlich lernen müssen: Selbst wenn eine Anlage als beispielsweise Euromap 77 kompatibel verkauft wird, sind nicht zwangsläufig alle Variablen aus dem Standard auf dem OPC UA Server zu finden. Es heißt nur, dass die Variablen, die auf dem Server verfügbar sind (und auch nur die, die im Standard definiert sind!), der spezifizierten Namensgebung folgen.
Sie sind in einer anderen Branche unterwegs und haben dort bessere Erfahrungen gemacht? Wir freuen uns sehr über eine Mail an hello@enlyze.com und einen interessanten Austausch!
🔍 Eine Datenquelle, tausende Variablen
Bevor man sich nicht mit der Anlage verbunden hat, kann man nicht sagen, wie viele Variablen auf einer Steuerung vorhanden sind. In den vergangenen fünf Jahren haben wir alles zwischen 10 und 1.000.000 Variablen pro Datenquelle gesehen. Daher ist es nicht einfach, den Aufwand einzuschätzen, um die wenigen relevanten Prozessgrößen zu finden.
Die durchschnittliche Datenquelle auf der ENLYZE Plattform verzeichnet 13.607,55 mögliche Variablen, von denen ca. 67 je Datenquelle aufgezeichnet werden. Oder auf gut Deutsch: Man muss zigtausend Variablen durchsuchen, um die relevanten 0,5 % zu finden.
Muss diese Tätigkeit auch noch in der Werkshalle vorgenommen werden, während 300 kg geschmolzener Kunststoff pro Stunde durch einen Ring in die Höhe geschossen werden, dann ist dies keine angenehme Tätigkeit.
Erschwerend kommt hinzu, dass es in den seltensten Fällen mit einer Anlage getan ist - man muss an jede Anlage ran. Wenn man dann noch die fehlende Standardisierung der Variablenbezeichnungen mit in Betracht zieht, haben wir volles Verständnis dafür, dass Unternehmen vor dieser Herausforderung zurückschrecken. Vor allem, weil damit allein auch noch kein Mehrwert geschaffen wird.
⛑️ Datenharmonisierung: Wie Euromap, nur für all Ihre Use-Cases
Produzierende Unternehmen müssen auf dem Weg Richtung Industrie 4.0 die Skalierbarkeit der Anwendungsfälle als eines der Hauptziele ihrer Strategie definieren.
Damit die in den oben erläuterten Punkten beschriebene Arbeit nur einmal und dann nie wieder gemacht werden muss, gilt es, eine Abstraktionsschicht zu bauen, die die Komplexität der Anlagen und Datenquellen zurückhält.
Dies wird durch die Harmonisierung der Daten erreicht: Ein unternehmensweites Daten- und Informationsmodell bildet Anlagen, relevante Prozessgrößen und Aggregationen wie KPIs, Energieverbräuche und CO2-Äquivalente ab und gibt diesen einen Bezeichner (identifier), der zum Abfragen der Daten unabhängig der darunterliegenden Anlage genutzt werden kann.
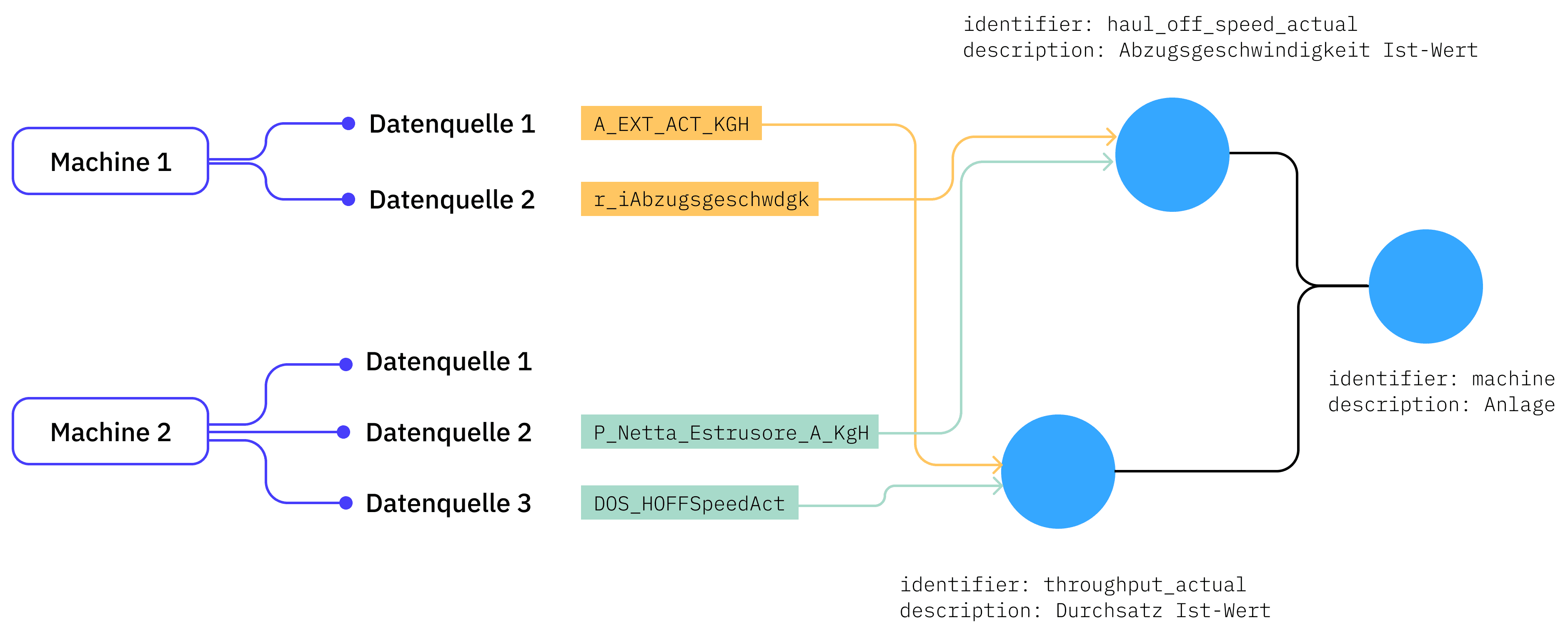
Ein stark vereinfachtes Informationsmodell ist in der obigen Abbildung dargestellt: Es wird ein Konzept einer Anlage (mit identifier "machine") und zwei Prozessgrößen, die Abzugsgeschwindigkeit (identifier "haul_off_speed_actual") und der Durchsatz (identifier "throughput_actual"), die einer Anlage zugehörig sind, definiert.
Jede Anlage wird nun zusammen mit den beiden Prozessgrößen in dem Informationsmodell angelegt und die Variablen der Anlagen mit den jeweiligen Prozessgrößen im Informationsmodell verknüpft: In unserem Beispiel verbirgt sich bei Maschine 1 der Durchsatz auf Datenquelle 1 hinter dem Tag "A_EXT_ACT_KGH" und die Abzugsgeschwindigkeit hinter dem Tag "r_iAbzugsgeschwdgk". Auf Maschine 2 hingegen verbirgt sich der Durchsatz hinter dem Tag "P_Netta_Estrusore_A_KgH" auf Datenquelle 2 und die Abzugsgeschwindigkeit hinter "P_Dati_Motore_A_Mt_Minuto" auf Datenquelle 3.
Nach erfolgter Zuordnung können nun Nutzer:innen und Applikationen die Abzugsgeschwindigkeit für jede Anlage über den identifier haul_off_speed_actual im Datenmodell abfragen, ohne zu wissen, dass dieser sich für Maschine 1 hinter "r_iAbzugsgeschwdgk" und für Maschine 2 hinter "P_Dati_Motore_A_Mt_Minuto" verbirgt.
Der Aufbau und das Verknüpfen eines Informationsmodells sind kein geringer Aufwand, aber die Mehrwerte sind enorm: Anders als derzeit in der Industrie gibt es lediglich einen einmaligen großen Integrationsaufwand für den ersten Anwendungsfall. Es werden Edge-Devices installiert, Steuerungen angeschlossen, das Informationsmodell aufgebaut, relevante Variablen auf den Steuerungen identifiziert und mit dem Modell verknüpft.
Darauffolgende Anwendungsfälle können jedoch auf dieser geschaffenen Plattform mit äußerst geringen Aufwänden aufgebaut werden.
Prozessingeneur:innen müssen nicht mehr mit USB-Sticks alle zwei Stunden an die Anlage rennen, um für 5 Minuten Daten von verschiedenen Anlagen aufzunehmen und hinterher in Excel die einzelnen Prozessgrößen übereinanderzulegen. Ebenfalls lassen sich Applikationen, die etwa den Product Carbon Footprint erfassen, schnell an einer Anlage testen und dann auf den gesamten Anlagenpark ausrollen. So kommt's, dass sobald die Anlagen digitalisiert und im Informationsmodell abgebildet sind, sog. Skaleneffekte greifen, wie wir sie in den vergangenen 30 Jahren bei Softwareunternehmen beobachten konnten.
Fazit
Der fehlende globale Standard für die Benennung von Variablen auf Steuerungsebene führt zu enormen Arbeitsaufwänden, wenn man bestimmte Variablensets in einem Anlagenpark erfassen möchte. Jedes Mal muss man sich durch Tausende Variablen mit neuen kryptischen Namensschemata kämpfen und die sprichwörtliche Nadel im Heuhaufen suchen.
Um diesen Aufwand nur einmal und nie wieder betreiben zu müssen, ist eine zentrale Komponente von IIoT-Plattformen die Harmonisierung der Daten. Durch die Erstellung und Zuweisung eines unternehmensweiten Namensschemas können Anwendungen und Dienste über Anlagen hinweg dieselben Variablennamen verwenden, um auf denselben physischen Wert, wie z. B. den Extruderdurchsatz oder die Düsengeschwindigkeit, zuzugreifen. Dadurch wird die Komplexität reduziert und eine schnelle Entwicklung eigener Anwendungen und Dienste ermöglicht.
Bei ENLYZE befassen wir uns seit fünf Jahren mit dieser Thematik und mussten diese Probleme zunächst selbst lösen, um unsere Anwendung für die Produktion schnell ausrollen zu können. In dem folgenden Artikel werden wir auf das heutige Thema näher eingehen und zeigen, wie man mit der ENLYZE IIoT-Plattform bequem und von überall Variablen in Anlagen erkunden und ein einheitliches Namensschema aufbauen kann.
Falls Sie in der Zwischenzeit Fragen, Feedback oder eine gegenteilige Meinung haben, können Sie sich gerne per E-Mail bei uns melden: hello@enlyze.com. Wir freuen uns, von Ihnen zu hören.
Übersicht Blogreihe Konnektivität & Maschinendaten:
Digitalisierungs-Dilemma: Für die Daten arbeiten oder mit den Daten arbeiten
Von Euromap, Datenblöcken und harmonisierten Daten
Mit ENLYZE und Grafana bereit für alle Herausforderungen in der Produktion

subscribe
Weiterlesen


